
 Mar 17, 2026
Mar 17, 2026 Table of Contents
Software safety requirements define the testable rules that keep software from causing harm—especially when something fails, data is wrong, or users make mistakes.
This article gives you a practical checklist, industry-specific expectations (ISO/IEC and related standards), and writing guidance so your team can turn “safety” into clear requirements that engineers can implement and auditors can verify.
What Are Software Safety Requirements?
Software safety requirements describe mandatory behaviors and constraints that reduce risk when software interacts with people, equipment, money, or critical operations. They sit above “normal” functional requirements because the goal is not just to work—it’s to fail safely, detect dangerous states early, and keep the impact contained.
From what we see in real projects, safety requirements become practical only when they’re written in a way engineers and testers can verify. If a requirement can’t be tested, it usually turns into a debate later.
Quick examples of software safety requirements
- Fail-safe on fault (IEC 61508 / ISO 26262):
If a safety-critical sensor signal is missing, stale, or out of range for more than X ms, the system shall enter a predefined safe state within 200 ms, inhibit hazardous outputs, and raise a high-priority alarm.
- Input validation + secure coding (OWASP / NIST SSDF):
The system shall validate and sanitize all external inputs, reject out-of-range or malformed commands, and prevent injection-style payloads through allowlists and parameterized handling.
- Access control for safety parameters (ISO 27001 / ISO/SAE 21434):
Only authorized roles shall modify safety thresholds using RBAC and MFA; all changes shall be audit-logged with user ID, timestamp, and before/after values.
- Secure communications for safety signals (IEC 62443 / ISO/SAE 21434):
Safety-critical commands and telemetry sent over networks shall use authenticated and encrypted transport (e.g., TLS) and message integrity checks; unauthenticated or modified messages shall be rejected.
- Alarm and escalation policy (IEC 61508 / IEC 62304):
If a safety-critical limit is exceeded, the system shall trigger a prioritized alarm, display operator guidance, require acknowledgement within X minutes, and escalate if acknowledgement is not received.
If you share the domain (medical, automotive, industrial, aviation, fintech), I can tailor the examples to the ISO standard that typically applies and the most common safety hazards in that space.
If your product needs safety-by-design architecture and verifiable testing evidence, our software development team can help implement these requirements cleanly and document them for audits.
Why Software Safety Requirements Are Important
Safety requirements turn “we should be careful” into specific, testable behaviors. Without them, teams ship features that work in normal conditions but behave unpredictably under faults, misuse, or edge cases—the exact moments where safety risk lives. In my experience, the worst incidents don’t come from one dramatic bug; they come from missing guardrails: unclear safe states, weak validation, vague alarms, and undefined recovery behavior.
They also protect the business when software fails at scale. Significant outages remain a major financial risk—Uptime Institute’s 2025 Annual Outage Analysis found that 54% of respondents reported their most recent significant outage cost more than $100,000, with one in five impactful outages exceeding $1 million. These figures highlight a persistent trend: even as outage frequency gradually declines, the cost of downtime continues to rise due to increased reliance on high-density AI workloads and third-party cloud dependencies. These costs include more than lost revenue: they encompass regulatory fines, customer trust damage, and a significant “productivity tax” on engineering teams.
Finally, safety requirements reduce recall and regulatory exposure in safety-critical domains. Software issues are a known driver of medical device recalls; IEEE Spectrum reported software problems are responsible for about 20 medical device recalls per month (2025 analysis). Clear safety requirements—especially around fault handling, alarms, access control, and traceability—are one of the most practical ways to prevent that kind of outcome.
Types of Software Safety Requirements
Software safety requirements typically fall into a few clear buckets—each one controls risk from a different angle.
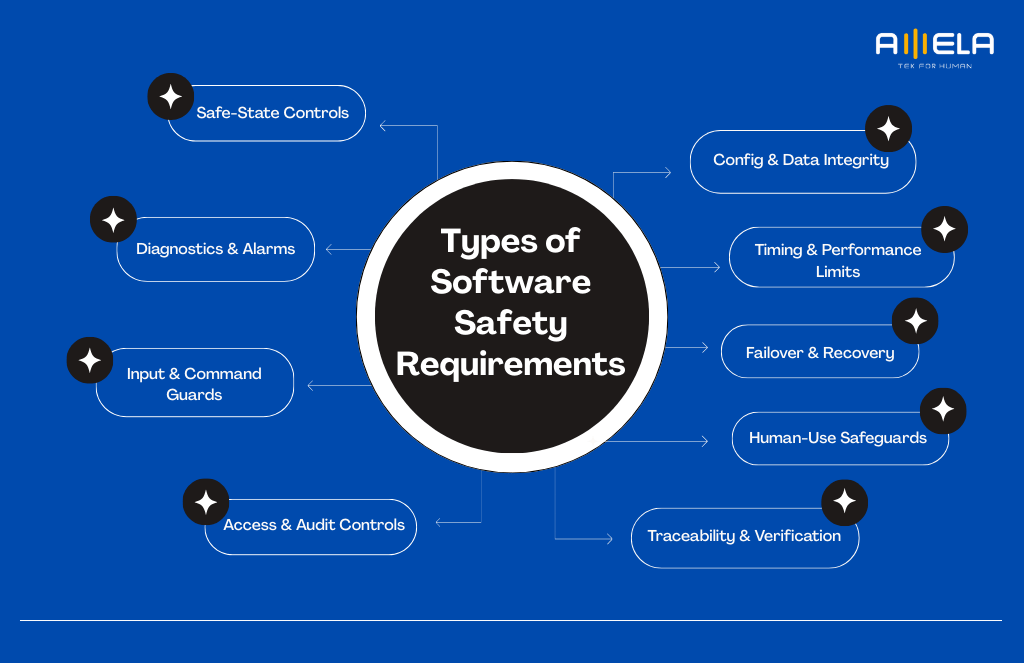
Safe-State Controls
These define what the software must do to prevent or contain harm when unsafe conditions occur. They usually specify safe states, trigger conditions, and timing.
Example: “If a safety-critical sensor signal is lost, the system shall enter safe mode within X ms.”
Diagnostics & Alarms
These cover how the system detects abnormal states, flags them, and guides response. They include alarm priority, clarity of messages, and escalation rules.
Example: “If threshold Y is exceeded, the system shall raise a high-priority alarm and require acknowledgement.”
Input & Command Guards
These prevent unsafe operations caused by invalid inputs, corrupted messages, or user mistakes. They define validation rules, range checks, and protection against unsafe sequences.
Example: “The system shall reject commands outside approved ranges and log the attempt.”
Access & Audit Controls
These restrict who can change safety-relevant settings and ensure changes are traceable. They typically include authentication strength, role-based access, and auditing.
Example: “Only authorized roles may modify safety limits; all changes shall be logged with user ID and timestamp.”
Config & Data Integrity
These ensure safety-relevant data is accurate, consistent, and recoverable. Versioning, checksums/signatures, and rollback rules often live here.
Example: “Safety configuration shall be versioned and restoreable to the last known-good state.”
Timing & Performance Limits
Many safety hazards are time-related. These requirements define latency limits, update rates, watchdog timers, and deadline behavior under load.
Example: “The control loop shall execute within X ms under normal and degraded conditions.”
Failover & Recovery
These specify how the system behaves when components fail: redundancy, fallback behavior, restart logic, and recovery steps. The key is predictable behavior under failure.
Example: “If the primary service fails, the system shall switch to backup with no more than X seconds of interruption.”
If failover and recovery are hard to implement cleanly, a focused software reengineering phase can simplify dependencies and make safety behavior more predictable.
Human-Use Safeguards
These focus on how users interact with safety-critical functions: UI clarity, confirmations for dangerous actions, lockouts, and error messages that reduce misuse.
Example: “Dangerous operations shall require two-step confirmation and show clear consequences.”
Traceability & Verification
Safety work must be provable. These requirements define traceability from hazard → requirement → test, plus evidence artifacts needed for audits and certification.
Example: “Each safety requirement shall have at least one verification test with recorded evidence.”
How to Write Software Safety Requirements
Write software safety requirements so they’re testable, traceable to a hazard, and unambiguous under failure.
Key components every good safety requirement includes
A safety requirement is strongest when it answers these questions clearly:
1. Hazard linkage and safety intent
Every safety requirement should trace back to a hazard analysis artifact, not a vague “best practice.” In safety work, that typically means a link to HARA / Hazard Analysis, FMEA, or FTA, plus the defined hazardous event and intended risk reduction. If you’re in regulated domains, you’ll also see SIL/ASIL targets or safety classification tied to the requirement.
2. Operational context and assumptions
Safety requirements must state the operating mode and context where they apply: normal mode, degraded mode, maintenance mode, emergency mode, commissioning mode. Also document assumptions and boundaries: expected sensor ranges, network conditions, user roles, environmental constraints. Auditors look for these because safety behavior often changes by mode.
3. Trigger condition and detection criteria
A safety requirement needs precise trigger definitions, including abnormal conditions. Common terms here include:
- Fault detection, timeout, loss of signal, out-of-range, sequence violation
- Plausibility checks, sanity checks, debouncing, threshold hysteresis
This is where teams prevent “it depends” arguments later.
4. Safety mechanism and required response
This is the “control” that reduces risk, written as explicit behavior:
- Fail-safe, fail-operational, safe state, safe stop
- Interlocks, inhibit, clamp/limit, lockout
- Degraded mode, fallback, graceful shutdown
A good requirement specifies the mechanism, not just the intention.
5. Timing constraints and deterministic behavior
In many systems, safety is time-bound. Use concrete timing language:
- Response time, latency, jitter, watchdog intervals, retry windows
- WCET (worst-case execution time) when relevant
If timing is left vague, verification becomes impossible.
6. Integrity and correctness of safety inputs/outputs
Safety requirements should cover how safety-relevant data is protected:
- CRC/checksum, message counters, sequence numbers
- configuration validation, range constraints, default-safe values
This prevents silent corruption from turning into unsafe behavior.
7. Access control for safety-relevant functions
Safety breaks when someone can change thresholds or bypass controls casually. Include:
- RBAC (least privilege), MFA for admin actions
- privileged operation gating, approvals for safety configuration changes
This is the point where security becomes directly safety-relevant.
When safety depends on preventing unauthorized changes or tampering, treat security controls as safety requirements—our Cybersecurity Services can help you design access, audit, and secure SDLC guardrails.
8. Traceability and safety evidence expectations
Safety work needs proof. Each requirement should specify:
- Requirement ID, bidirectional traceability to hazard → design → test
- Safety case/evidence artifacts: verification records, test logs, review approvals
People often underestimate this until certification time.
9. Verification method and acceptance criteria
State how you’ll verify: test, analysis, inspection, simulation, fault injection. Then define acceptance criteria clearly. For higher integrity systems, verification language may include:
- SIL/HIL testing (software-in-the-loop / hardware-in-the-loop)
- Coverage expectations (e.g., code coverage or MC/DC in some standards)
Even if you don’t publish the full test plan, the requirement should be verifiable.
If you’re validating safety assumptions early, aligning the effort to the right stage matters—this breakdown of PoC vs prototype vs MVP helps choose a safer path before scaling development.
10. Exception handling and human interaction
Real systems live in edge cases. Requirements should address:
- Operator alerts, acknowledgement behavior, escalation rules
- Safe manual override rules (when allowed), UI confirmations for hazardous actions
Human factors matter more than teams admit.
Practical writing rules that keep requirements “certifiable”
- Use “shall” for mandatory behavior. Avoid “should,” “may,” “as soon as possible.”
- Make it measurable. Add thresholds, ranges, and timing where safety depends on it.
- Describe failure behavior. Normal behavior is easy; safety lives in degraded modes.
- Avoid combined requirements. One requirement = one behavior (easier to test and audit).
- Define terms once. “Safe mode,” “critical alarm,” “operator” should be explicit.
A simple pattern that works (copy-friendly)
[ID] The system shall [action] when [trigger/condition] within [time] to achieve [safe outcome]. Verification: [method].
Examples (good vs weak)
- Weak: “The system should prevent unsafe commands.” Better: “The system shall reject motion commands exceeding configured limits and log the rejection with timestamp and user ID.”
- Weak: “The system shall handle sensor failures safely.” Better: “If sensor S is missing for >200 ms, the system shall enter Safe Mode A and display Alarm P1 within 500 ms.”
Add security where it directly affects safety
In many real systems, safety can be compromised through access or tampering, so include requirements like:
- Safety function access control: only specific roles can modify thresholds
- Audit logging: safety-relevant changes logged and reviewable
- Integrity checks: configs versioned and recoverable to last known-good state
Use the right kind of external expertise when needed
If you’re building in regulated or high-risk domains, it’s common to involve independent safety/certification and security specialists to review requirements, traceability, and evidence expectations. Examples of well-known organizations in this space include:
- Functional safety / certification & testing: TÜV SÜD, TÜV Rheinland, UL Solutions, SGS, DEKRA, DNV, exida
- Product security firms (when cyber risk impacts safety): NCC Group, Trail of Bits
These firms don’t replace your engineering work—but they’re useful for validating that your requirements and evidence approach will stand up to audits and real-world failure conditions.
If you’re still defining scope and architecture before writing requirements, this custom software development guide explains how to structure discovery and documentation so delivery stays controlled.
Software Security Requirements Checklist by Standard
Use this standards-based checklist to map each safety requirement to the ISO/IEC framework your project must comply with.
| Checklist area | What to check (copy-friendly) | Typical evidence | ISO/IEC standards |
| Hazard analysis & risk classification | Hazards identified; severity/likelihood assessed; risk controls defined; SIL/ASIL or safety class assigned where applicable | Hazard log, HARA/FMEA/FTA outputs, risk matrix | IEC 61508, ISO 26262, IEC 62304, ISO 14971 |
| Safety requirements quality | Requirements use “shall”; measurable triggers; single behavior per requirement; no vague terms (“as soon as possible”) | Requirements spec, review checklist | IEC 61508, ISO 26262, IEC 62304 |
| Operating modes & assumptions | Safety behavior defined per mode (normal/degraded/maintenance/emergency); assumptions documented | Mode definitions, state diagrams, safety concept | IEC 61508, ISO 26262, IEC 62304 |
| Safe state & fail-safe behavior | Safe state defined; entry/exit criteria; safe stop / inhibit / lockout rules; degraded mode logic | Safety concept, state machine, fault-response table | IEC 61508, ISO 26262 |
| Fault detection & diagnostics | Fault detection rules, timeouts, plausibility checks, watchdogs; diagnostic coverage targets (if required) | Diagnostic spec, fault injection results | IEC 61508, ISO 26262 |
| Timing & performance constraints | Response time limits, WCET targets (if needed), latency/jitter constraints, retry windows | Timing tests, performance reports | IEC 61508, ISO 26262 |
| Input validation & command safety | Range checks, sequence checks, anti-replay/counter checks where relevant; unsafe command rejection behavior | Test cases, secure coding checklist | IEC 61508, ISO 26262, IEC 62304 |
| Access control for safety functions | RBAC/least privilege; MFA for admin actions; safety parameter change restrictions | Access policy, audit logs, IAM configs | ISO/IEC 27001, ISO/IEC 27002, ISO/SAE 21434 |
| Data integrity & config control | Versioned safety configs; integrity checks (checksum/CRC/signature); rollback to last-known-good | Config management plan, change logs | ISO/IEC 27001, ISO/IEC 27002, plus domain safety standard |
| Secure development lifecycle | Threat modeling, secure code reviews, SAST/DAST gates, vulnerability remediation rules | SDLC policy, scan reports, review records | ISO/IEC 27001, IEC 62443, NIST SSDF (not ISO) |
| Logging, audit trail & alarms | Safety events logged with timestamp/user/cause; alarm priorities; operator guidance; tamper-resistant logs | Log schema, alert rules, incident records | ISO/IEC 27001, IEC 62443, domain safety standard |
| Verification & validation (V&V) | Test strategy covers normal + fault scenarios; HIL/SIL where relevant; acceptance criteria defined | Test plan, test reports, trace matrix | IEC 61508, ISO 26262, IEC 62304 |
| Traceability & safety case evidence | Bidirectional trace: hazard → requirement → design → test → release; evidence packaged for audit | Trace matrix, safety case bundle | IEC 61508, ISO 26262, IEC 62304 |
| Supplier & software supply chain | SBOM where required; dependency scanning; code signing; third-party risk controls | SBOM, SCA reports, supplier agreements | ISO/IEC 27001, IEC 62443, ISO/SAE 21434 |
| Post-release monitoring & change control | Incident response plan; safety-related change approval; regression testing scope; rollback procedures | Runbooks, incident logs, release checklist | ISO/IEC 27001, domain safety standard |
Quick notes:
- ISO/IEC 27001/27002 = security management controls (often needed because security issues can create safety hazards).
- IEC 61508 / ISO 26262 / IEC 62304 = functional safety / safety lifecycle by domain.
- ISO/SAE 21434 = automotive cybersecurity (commonly paired with ISO 26262).
Industry Software Safety Specification Checklist
Use this industry checklist to capture the safety requirements that matter most for your domain and avoid missing compliance-critical items.
| Industry | Safety/security requirements | Typical artifacts to demand | Key standards used |
| Automotive (ECU, ADAS, connected vehicles) | Hazard analysis with ASIL targets; safe state + degraded mode; fault detection & diagnostics; timing constraints (watchdog/latency); safety-related config control; secure access for safety functions; traceability from hazard → test | HARA, safety goals, technical safety concept, safety requirements spec, trace matrix, test evidence (incl. fault scenarios) | ISO 26262, ISO/SAE 21434 |
| Medical devices (software in/with devices) | Patient harm hazard analysis; software safety classification; alarms and operator guidance; data integrity for clinical outputs; fail-safe behavior; change control and regression scope; security controls for safety-relevant data | Risk management file, software requirements spec, verification plan, traceability matrix, test reports, release records | IEC 62304, ISO 14971, (security often aligned with IEC 81001-5-1 depending on org) |
| Industrial automation / OT systems (SCADA, PLC-adjacent apps) | Defined safe shutdown/stop behavior; interlocks; exception handling; timing requirements; audit logging; access control; segmentation assumptions; supplier component constraints | Safety function spec, control logic requirements, alarm philosophy, change management logs, incident runbooks | IEC 61508, IEC 62443 |
| Aviation (airborne software) | Requirements tied to system safety assessment; strict traceability; deterministic behavior; coverage expectations; configuration management discipline; verification independence | PSAC, requirements data, traceability, verification cases/results, CM plan, audit evidence | DO-178C (not ISO), plus system safety processes in aviation standards |
| Rail / transportation (signaling, control) | Hazard analysis + fail-safe state; redundancy/fallback rules; timing constraints; safety integrity targets; operator alerts; configuration control; end-to-end traceability | Hazard log, safety requirements, V&V reports, trace matrix, operational procedures | EN 50128 (not ISO), often with related rail safety standards |
| Energy & utilities (grid, monitoring, critical ops) | Safe operating boundaries; alarms and escalation; reliability and recovery behavior; access control; auditability; incident handling; supplier management | Operational safety requirements, monitoring/alert specs, incident runbooks, compliance evidence | IEC 61508, IEC 62443 (plus sector regulations) |
Conclusion
Software safety requirements are not paperwork—they are engineering controls that reduce risk, prevent costly incidents, and make delivery more predictable in safety-critical environments. When requirements are hazard-linked, measurable, and traceable through design and testing, teams move faster with fewer disputes and stronger compliance readiness. If you need help defining safety requirements, building verification evidence, or delivering safety-aware software with disciplined execution, AMELA Technology can support your project from planning to implementation and validation.



